Visual Understanding: Object Detection vs OCR vs VLM | by Edgar Trujillo | Medium

Beyond Surface-Level Image Analysis
When developing applications that rely on image understanding, developers encounter a crucial decision: which visual AI approach best meets their needs? Should they focus on detecting objects, extracting text, or utilizing more advanced vision-language models? Based on my experience building a travel recommendation app, I found that the answer isn’t always straightforward.
The Problem: Making Travel Content Actionable
Like many other millennials who’ve caught the travel bug, I often find myself mindlessly scrolling through Instagram and TikTok, saving countless travel reels with the intention of visiting these places someday. But when it actually comes time to plan a trip, I’m left with a disorganized collection of videos and no easy way to transform them into an actual itinerary.
My journey began with a seemingly simple goal: create a mobile app that could transform social media travel content (specifically Instagram and TikTok reels) into actionable travel information. The concept was straightforward — “See it, save it, go there.” This eventually became ThatSpot Guide which is now available on App Store.
Users would share travel-related reels with the app, and our AI agents would automatically extract key insights:
- Determine if the content was a single recommendation, a list, or a suggested itinerary
- Identify entities like cafes, restaurants, or attractions
- Gather necessary information about each place (location, price range, reservation details, menu highlights)
- Provide direct booking links where applicable
The end result? Users could skip the tedious process of manually searching Google or Maps when planning their trips. While traveling, they could open the map-based explore tab and discover nearby places featured in their saved reels.
Zoom image will be displayed
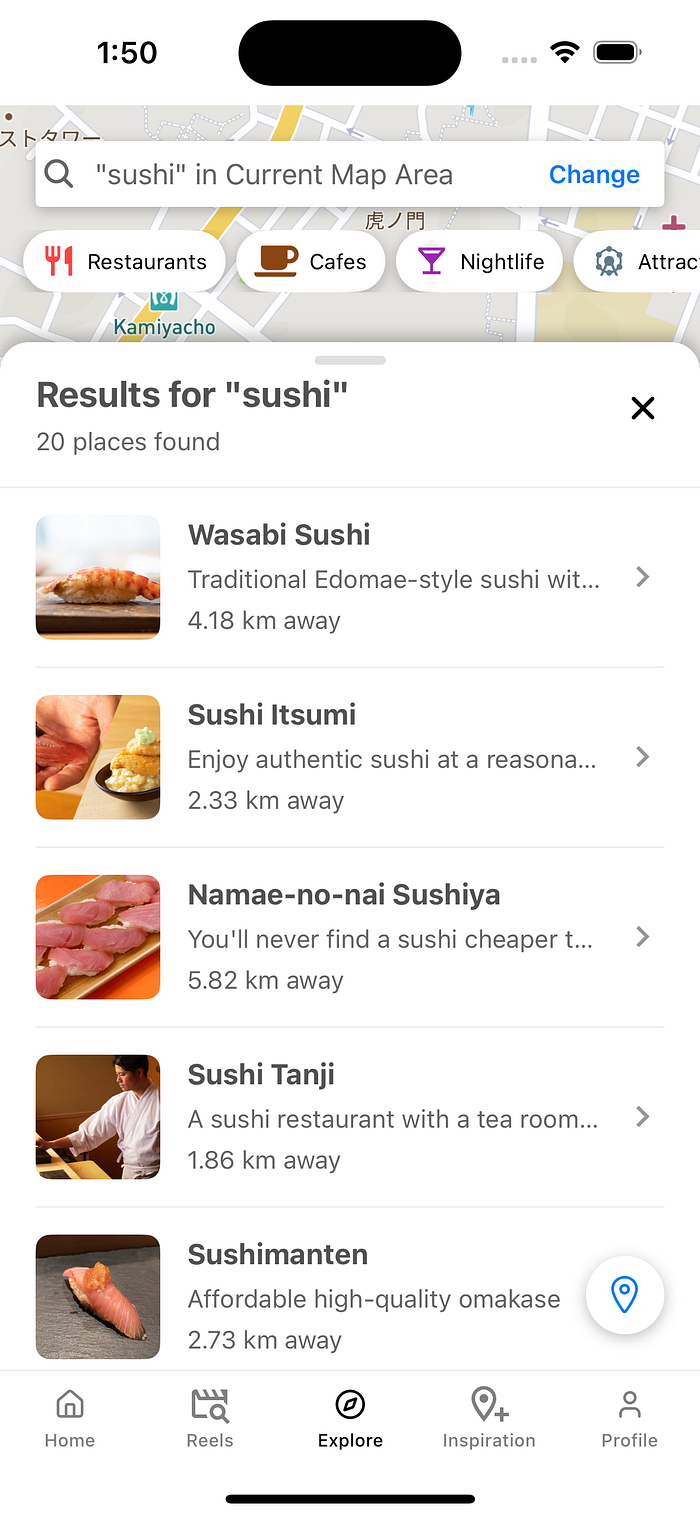
It was a great concept, but the technical implementation posed significant challenges, particularly visual understanding.
The Trial and Error Process
Zoom image will be displayed

Like many developers, I initially approached the problem with the most common visual AI techniques:
Object Detection
My first attempt employed object detection (using YOLO) to identify visual elements in the reels. For a sample image of a rooftop restaurant in Mexico City, the model returned:
<span id="1c8d" data-selectable-paragraph="">chair, chair, dining table, chair, couch</span>

While technically accurate, this information was virtually useless for my application. Knowing there are chairs and tables in a restaurant doesn’t help users decide whether to visit.
Optical Character Recognition (OCR)
Next, I tried text extraction using Google’s Text Detection and AWS Textract. Both returned nearly identical results:
<span id="0ef3" data-selectable-paragraph="">This roofless bar in Mexico City lives rent free in my head</span>
Zoom image will be displayed
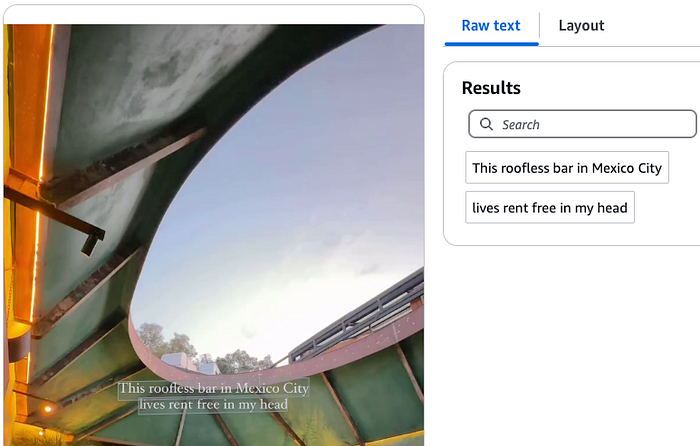
This was more helpful, providing location context, but still lacked the comprehensive information needed for travel planning.
Basic Image Captioning
Moving up the complexity ladder, I tested a basic image captioning model (BLIP) which returned:
<span id="6674" data-selectable-paragraph="">the restaurant at the resort</span>

Another technically correct but practically unhelpful result.
The Breakthrough: Vision Language Models
The game-changer came when I shifted from these traditional approaches to using a Vision Language Model (VLM) with a specific prompt strategy. Instead of asking for object detection or caption generation, I prompted the model to describe the image composition in detail.
I tested Moondream 2B, a relatively small (2 billion parameters) but efficient open-source VLM. Despite its modest size compared to behemoths like GPT-4V, the results were remarkably more helpful:
Zoom image will be displayed

This comprehensive description provided:
- The nature of the establishment (rooftop bar/restaurant)
- The ambiance (cozy, inviting atmosphere)
- Visual details (green roof, plants, various seating options)
- Geographic context (Mexico City)
- The sentiment expressed by the original poster (“lives rent free in my head” suggesting it’s highly memorable)
My application could extract meaningful information from this rich description to help users decide if this place matches their interests and preferences.
Key Insight: Context and Purpose Matter
The critical lesson from this experience wasn’t that VLMs are inherently superior to object detection or OCR. Instead, the appropriate visual AI approach depends entirely on your application’s specific needs and context.
If you’re building a security system that needs to detect intruders, simple object detection might be perfect. If you’re digitizing documents, OCR is the obvious choice. However, for applications requiring a nuanced understanding of visual content — especially those involving human preferences, experiences, and decision-making — the richer context provided by well-prompted VLMs often proves invaluable.
The Efficiency Factor: A Scrappy Bootstrap Approach
What’s particularly interesting is that this breakthrough didn’t require the most significant, computationally expensive models. Moondream 2B, with just 2 billion parameters, provided all the context needed when adequately prompted. The project even offers a 500 million parameter variant optimized for edge devices.
This efficiency is crucial for mobile applications where performance, battery life, and data usage are constant concerns.
Keeping Costs Down for a Side Project
As a side project built primarily to solve my own travel planning needs, budget constraints were real. While larger models like Claude VLM would undoubtedly work well for this task, they come with significant costs that quickly add up:

Beyond cost, using these API-based services would introduce other potential issues:
- Requiring image resizing (potentially losing important context)
- Higher API latency
- API service limits
The Modal.com Solution
My solution was to leverage Modal.com, a cloud platform designed for running, scaling, and deploying AI and ML workloads. Modal provides $30 of free cloud computing, which allowed me to create a custom GPU-enabled Moondream API instance without any upfront costs.
With Modal, I could:
- Access on-demand GPU resources only when needed
- Deploy the smaller, more efficient Moondream model as a serverless API
- Process images at full resolution without constraints
- Avoid the per-token pricing model of commercial APIs
- Control latency and eliminate service limits
The entire setup process was straightforward, using Modal’s Python-first development approach. I simply wrote code to load and serve the Moondream model, and Modal handled all the container orchestration, scaling, and infrastructure management behind the scenes.
Open-Sourcing the Solution
In the spirit of giving back to the developer community, I’ve open-sourced my Modal Moondream implementation. You can find the complete code, setup instructions, and documentation in my GitHub repository: https://github.com/edgarrt/modal-moondream.
The repository includes:
- Ready-to-deploy Modal functions for serving Moondream
- Examples of described prompting strategies
Feel free to fork, modify, and use this implementation for your own projects. If you’re working on a budget-conscious side project that requires visual understanding capabilities, this might save you significant time and resources.
This approach exemplifies the “scrappy startup” mentality that’s sometimes required for side projects — finding creative ways to leverage available resources rather than immediately jumping to the most expensive, enterprise-grade solution.
Looking Forward: The Right Tool for the Job
As AI vision technology evolves, the distinctions between these approaches may blur. Future systems might seamlessly integrate object detection, text recognition, and contextual understanding. But for now, developers must carefully consider what type of visual understanding their application requires.
Building my travel app taught me that the most obvious approach isn’t always the most effective. Beyond detecting what’s in an image or extracting text, understanding the composition, context, and meaning often delivers the most value.
The next time you implement visual AI in your application, consider not just what’s in the image but what the image means to your users. That perspective might lead you to a different technical approach than initially planned.
Final Thoughts
Visual understanding in AI isn’t a one-size-fits-all proposition. Object detection, OCR, and VLMs serve different purposes and excel in various contexts. Your application’s specific needs should guide your choice of technology, and sometimes, as in my case, the best solution might involve using these technologies in novel ways or with carefully crafted prompts.
For my travel app, a well-prompted VLM delivered the contextual understanding needed to transform passive social media content into actionable travel recommendations. Your application might require a different approach entirely, and that’s perfectly fine. The key is matching the technology to your specific use case rather than simply choosing the newest or most advanced option.
If you’re interested in seeing how these visual AI approaches come together in a practical travel planning tool, you can download ThatSpot Guide on the App Store or visit our website at https://thatspot.app for more information.
And don’t forget to check out the open-source implementation of the Modal Moondream API if you’re building something similar!